分布式集群文件批量同步工具
为了解决分布式集群中文件同步的问题,如快速同步 Hadoop 配置到其他节点,我们开发了一款名为"分布式集群文件批量同步工具"的工具。该工具旨在帮助用户高效地管理和同步大量数据在多个节点之间。
该工具基于 async,使用 FishShell 的 function,可以快速将文件改动同步到多个节点,支持文件同步、路径同步。
使用方法
该脚本可以接受0-2个参数,可以直接传入文件名:
- 不传入参数:直接同步当前路径到所有其他节点,目标节点路径与传入路径的绝对路径一致。。
- 一个参数:同步指定参数路径到所有节点,目标节点路径与传入路径的绝对路径一致。
- 两个参数:同步第一个参数路径到所有其他节点的第二个参数路径。
示例如下:
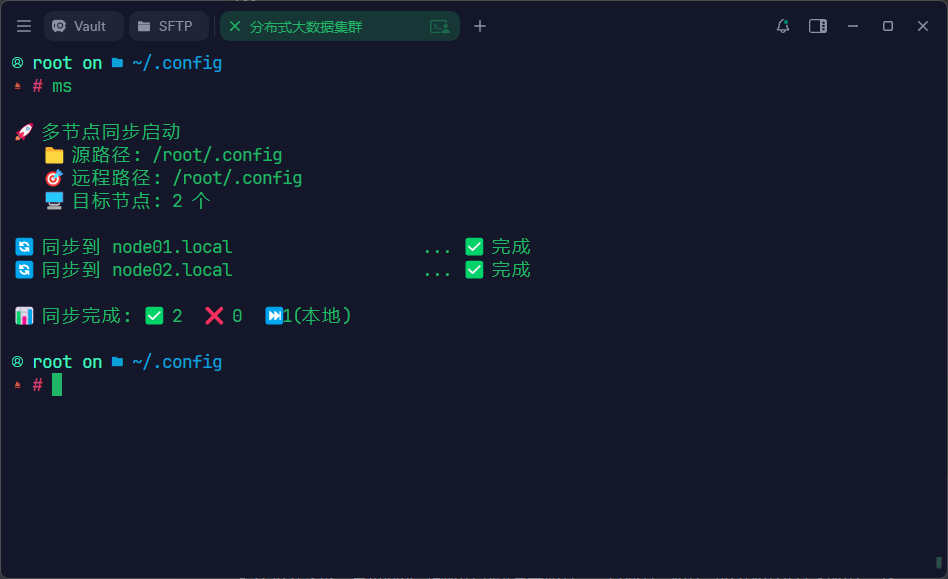
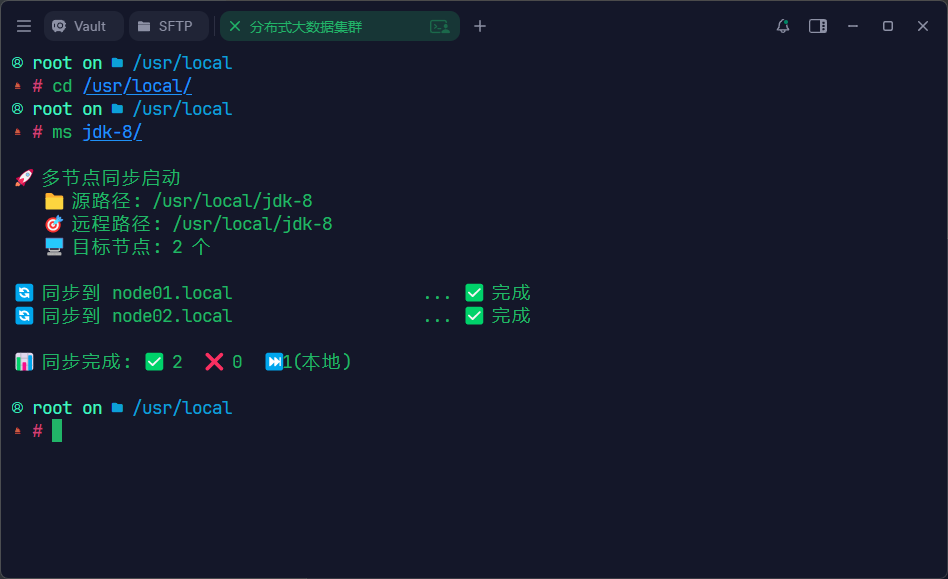
安装
需要在 ~/.config/ 下新建一个 nodes 文件,写入需要同步的节点(需要与 hostname 保持一致):
master.local
node01.local
node02.local将脚本文件写入 ~/.config/fish/functions/ms.fish即可:
bash
function ms --description "MuffinTool-Sync: 同步文件到多个远程节点"
# 配置路径
set -l nodes_file ~/.config/nodes
set -l verbose 0
# 检查是否是 verbose 模式
if contains -- --verbose $argv; or contains -- -v $argv
set verbose 1
set -e argv[(contains -i -- --verbose $argv)] 2>/dev/null
set -e argv[(contains -i -- -v $argv)] 2>/dev/null
end
# 检查配置文件是否存在
if not test -f $nodes_file
echo "❌ 错误:未找到配置文件 ~/.config/nodes"
echo "💡 请创建该文件并添加远程节点(每行一个):"
echo " echo \"user@server1\" >> ~/.config/nodes"
return 1
end
# 获取当前主机名(用于跳过本地节点)
set -l current_hostname (hostname)
# 读取节点列表(排除空行和注释)
set -l nodes (grep -v '^#' $nodes_file | grep -v '^[[:space:]]*$' | string trim)
if test (count $nodes) -eq 0
echo "⚠️ 警告:配置文件中没有有效的远程节点"
return 1
end
# 解析参数
set -l src_path
set -l remote_target
set -l is_file 0
switch (count $argv)
case 0
set src_path (pwd)
set remote_target $src_path
case 1
if string match -q "/*" $argv[1]
set src_path (string trim -r -c '/' $argv[1])
else
set src_path (string trim -r -c '/' (realpath $argv[1]))
end
set remote_target $src_path
case 2
if string match -q "/*" $argv[1]
set src_path (string trim -r -c '/' $argv[1])
else
set src_path (string trim -r -c '/' (realpath $argv[1]))
end
set remote_target (string trim -r -c '/' $argv[2])
case '*'
echo "❌ 用法错误"
echo " msy # 同步当前目录"
echo " msy <path> # 同步指定路径"
echo " msy <src> <dst> # 同步到远程指定路径"
echo " msy -v/--verbose # 显示详细日志"
return 1
end
# 验证源路径存在
if not test -e $src_path
echo "❌ 错误:源路径不存在: $src_path"
return 1
end
# 判断是文件还是目录
if test -f $src_path
set is_file 1
end
# 计算实际需要同步的节点数(排除本地)
set -l total_nodes 0
for node in $nodes
set -l node_hostname (string split '@' $node)[-1]
if test "$node_hostname" != "$current_hostname"
set total_nodes (math $total_nodes + 1)
end
end
if test $total_nodes -eq 0
echo "⚠️ 没有需要同步的远程节点(全部跳过)"
return 0
end
# 输出头部
echo ""
echo "🚀 多节点同步启动"
echo " 📁 源路径: $src_path"
echo " 🎯 远程路径: $remote_target"
echo " 🖥️ 目标节点: $total_nodes 个"
if test $verbose -eq 1
echo " 📢 详细模式: 开启"
end
echo ""
# 统计变量
set -l success_count 0
set -l fail_count 0
set -l skip_count 0
# 遍历所有节点执行同步
for node in $nodes
set -l node_hostname (string split '@' $node)[-1]
# 跳过本地节点
if test "$node_hostname" = "$current_hostname"
set skip_count (math $skip_count + 1)
continue
end
printf "🔄 同步到 %-30s ... " $node
if test $verbose -eq 1
echo ""
end
# 根据文件类型选择同步策略
if test $is_file -eq 1
# 文件同步:确保远程父目录存在,直接同步文件
set -l remote_dir (dirname $remote_target)
ssh $node "mkdir -p $remote_dir" 2>/dev/null
if test $verbose -eq 1
if rsync -az --delete -e ssh $src_path $node:$remote_target
echo "✅ 完成"
set success_count (math $success_count + 1)
else
echo "❌ 失败"
set fail_count (math $fail_count + 1)
end
else
if rsync -az --delete --quiet -e ssh $src_path $node:$remote_target 2>/dev/null
echo "✅ 完成"
set success_count (math $success_count + 1)
else
echo "❌ 失败"
set fail_count (math $fail_count + 1)
end
end
else
# 目录同步:使用增量算法,不删除远程目录,只同步变更
# --delete 会删除远程多余文件,但不会重新传输未变更文件
ssh $node "mkdir -p $remote_target" 2>/dev/null
if test $verbose -eq 1
if rsync -az --delete -e ssh $src_path/ $node:$remote_target/
echo "✅ 完成"
set success_count (math $success_count + 1)
else
echo "❌ 失败"
set fail_count (math $fail_count + 1)
end
else
if rsync -az --delete --quiet -e ssh $src_path/ $node:$remote_target/ 2>/dev/null
echo "✅ 完成"
set success_count (math $success_count + 1)
else
echo "❌ 失败"
set fail_count (math $fail_count + 1)
end
end
end
end
# 输出统计
echo ""
echo "📊 同步完成: ✅ $success_count ❌ $fail_count ⏭️ $skip_count(本地)"
echo ""
if test $fail_count -gt 0
return 1
end
return 0
end